What is Machine Learning?
Machine Learning (ML) is a subfield of AI that develops algorithms to automatically improve performance on a specific task from data, without being explicitly programmed to perform the task. For example, using historical price data to do well at the task of predicting future stock prices. Or using text data from the internet to do well at the task of engaging in human-like conversation.
ML has a rich, and at times fuzzy, history stemming from many fields including Statistics, Computational Statistics, Artificial intelligence and Computer Science.
Regardless of the precise definition of ML, there are a few essential ingredients: a specific user defined task, input data matching the task, a method or algorithm that uses the data to produce output results, and a way of evaluating the result.
 A machine diligently learning.
A machine diligently learning.
Source: DALL·E
Families of ML Algorithms
An algorithm is a set of rules used for solving a problem or performing a computation. There are several families of ML algorithms that typically have different qualities of input data and achieve different task objectives.
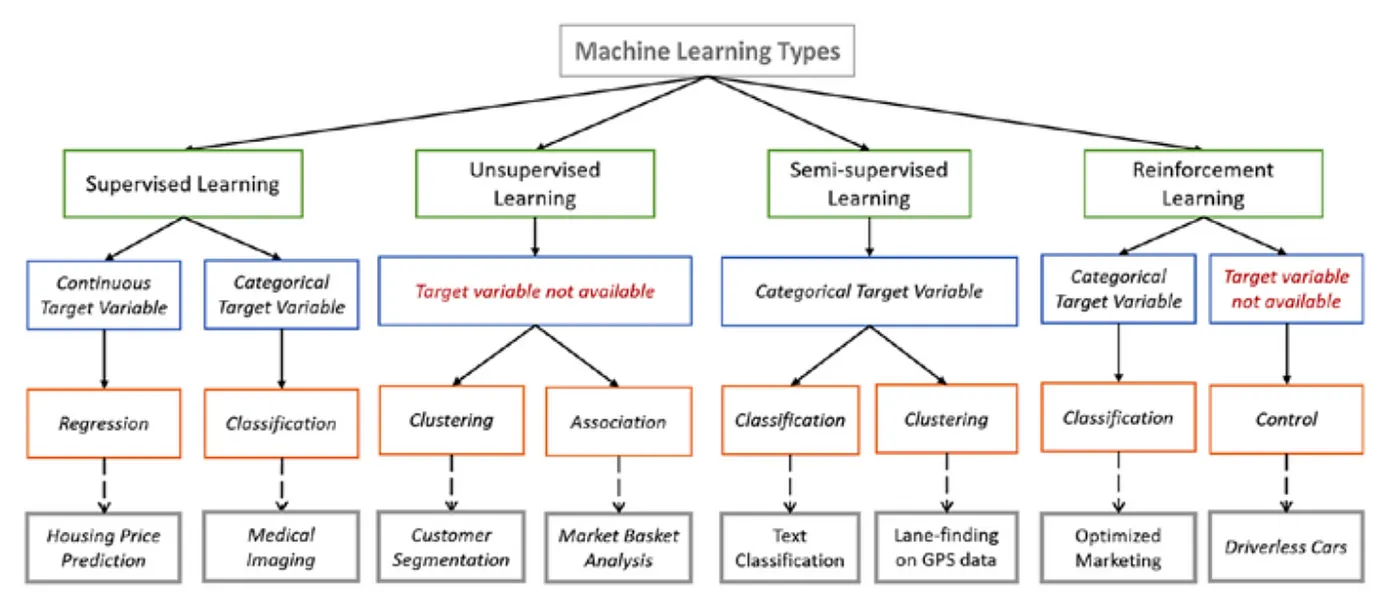 Machine Learning Types.
Machine Learning Types.
Source: en.proft.me
1. Supervised Learning
Supervised learning algorithms operate on labelled examples, where each data point has features (also known as attributes) and an associated known true label value. For example, features of a patient medical condition with a known label of the disease.
If you have labelled data, supervised learning algorithms learn a function that maps input feature vectors to the output label. Within supervised learning there are different types of algorithms depending on your data and task objective.
Classification algorithms are used when the outputs are restricted to a limited set of label values.
Regression algorithms are used when the outputs may have any numerical value.
2. Unsupervised Learning
If you have data with no labels, unsupervised learning algorithms can be used to discover patterns. Within unsupervised learning there are also different types of algorithms depending on your data and task objective.
Clustering, for example discovering customer segmentations based on behavioural patterns where the segments are unknown ahead of time.
Association mining, discovering interesting relations between features in large datasets, for example to power a product recommendation engine.
Dimensionality reduction, where data is transformed from a high dimension (with many features) into a lower dimension (fewer features). This can help with data visualisation, data summarisation and improve downstream efficiency for further analysis.
3. Semi-supervised Learning
Semi-supervised learning (also known as weak learning) is a middle ground between supervised and unsupervised approaches, especially when gathering supervised datasets is costly. This approach uses labelled and unlabelled data to create weak labels on the unlabelled subset and may produce better models than supervised methods alone.
Semi-supervised learning is widely used in many applications such as natural language processing, computer vision, and speech recognition, where labeled data is often scarce, but large amounts of unlabelled data are available.
4. Reinforcement learning
Reinforcement learning is quite different from the other methods described above. It is the training of an ML model that directs an agent to make a sequence of actions in an environment. For example, self-driving cars, playing chess, minimising energy consumption in data centres.
The agent interacts with the environment and receives feedback in the form of rewards or penalties, and uses this information to improve its decision making over time. Reinforcement learning well-suited for problems where it’s difficult to explicitly program an optimal solution, or where the optimal solution may change over time.
Due to its generality, reinforcement learning is studied in many disciplines, such as game theory, control theory, operations research, and multi-agent systems.
5. Deep learning
Deep learning involves training artificial neural networks (inspired by the structure of the brain) on large amounts of data and using the learned representations for a variety of tasks. The word “deep” in “deep learning” refers to the number of layers through which the data is transformed.
Deep learning is an approach that encompasses each of the families of algorithms described above. For supervised learning tasks, deep learning methods eliminate feature engineering, by translating the data into compact intermediate representations. An example of unsupervised deep learning is a Deep belief network, while Deep reinforcement learning is an active area of research.
Deep learning has been very successful in a variety of applications and has outperformed traditional machine learning algorithms on many tasks. This is partially due to an abundance of data and faster GPUs in recent years, as well as advancements in training methods.
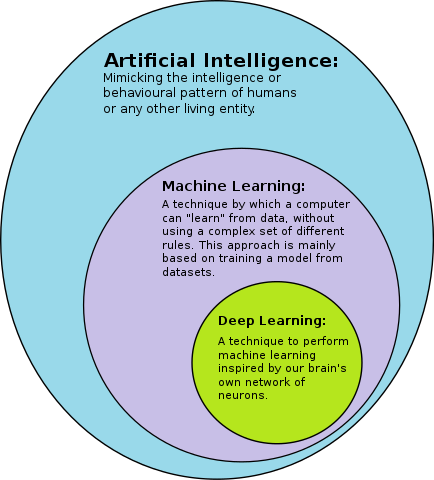 Deep learning in relation to ML and AI.
Deep learning in relation to ML and AI.
Source: Wikipedia
Which Algorithm Should I Use?
Choosing the right machine learning algorithm depends on a number of factors, including the type of problem you are trying to solve, the size and quality of your data, the desired interpretability of the result, and the computational resources you have available.
Identifying the family of algorithms based on your specific task is the first step, followed by trying one or more algorithms. Often there is no single “best” algorithm for a given problem. In many cases, an ensemble of multiple algorithms can produce better results than a single algorithm.
Here is a quick start cheat-sheet to help select an algorithm from the popular Python ML package, scikit-learn:
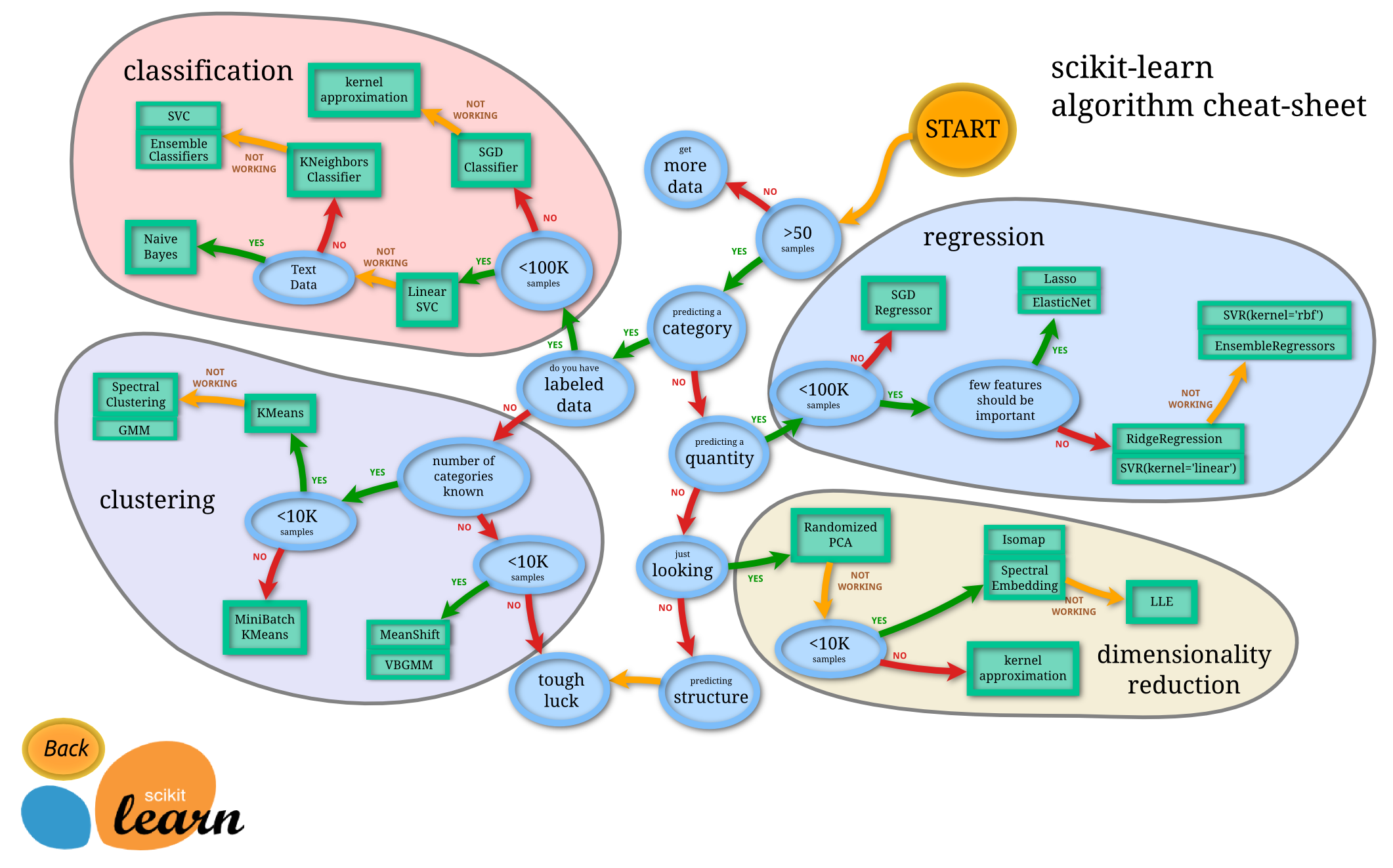 Algorithm selection cheat-sheet
Algorithm selection cheat-sheet
Source: scikit-learn
And here are a couple more algorithm selection cheat-sheets, from Datacamp and Microsoft.
Common Classification Algorithms
The following list gives you an idea of the more common classification algorithms. For a much broader list see Outline of Machine Learning on Wikipedia or the scikit-learn documentation.
- Logistic Regression – models the probability of an output
- Decision Trees – builds a tree branching on input values and class predictions in the leaves
- Random Forests and Gradient Boosted Machines – ensembles of decision trees
- Support Vector Machines – finds a maximum margin hyper-plane that differentiates two classes
- K-Nearest Neighbours Classification – an instance is classified by vote of its nearest neighbours
- Naïve Bayes Classifier – probabilistic classifiers with strong independence assumptions between the features
- Neural Networks, Deep Learning, LSTM’s, CNN’s, RNN’s
Types of ML Algorithms
It can be useful to understand the different types of algorithms and be aware of different qualities they may have from each other. For example:
-
Instance based algorithms - uses whole dataset as the model
E.g., kNN finds the most similar labelled instances for a given example and returns the most common label as predicted class -
Model based algorithms - uses training data to create a model with learned parameters
E.g., Logistic regression uses an optimisation algorithm to find optimal parameters. This model predicts a probability for a new instance belonging to a certain class -
Parametric algorithms – make assumptions about the mapping of the input variables to the output variable and can summarise the data with a set of parameters of fixed size (independent of the number of training examples)
E.g., Logistic Regression, Naive Bayes, Neural Networks -
Non-parametric algorithms – make few or no assumptions about the target function
E.g., kNN, Decision Trees, Support Vector Machines
Experimentation
Experimentation is important when developing a machine learning model. It allows testing of different hypotheses and evaluating the effectiveness of various algorithms, parameters, and architectures. This provides insights into the strengths and weaknesses of models, identifying areas for improvement to achieve better performance.
Experimentation also enables the practitioner to evaluate the model’s generalisation ability, which is crucial for ensuring that the model can make accurate predictions on unseen data. This aspect of training a model will be covered in a future post.
I recommend playing with the TensorFlow Playground which lets you create, run and experiment with simple neural networks on sample data. This is a great way to get a intuition about what a network can and cannot learn.
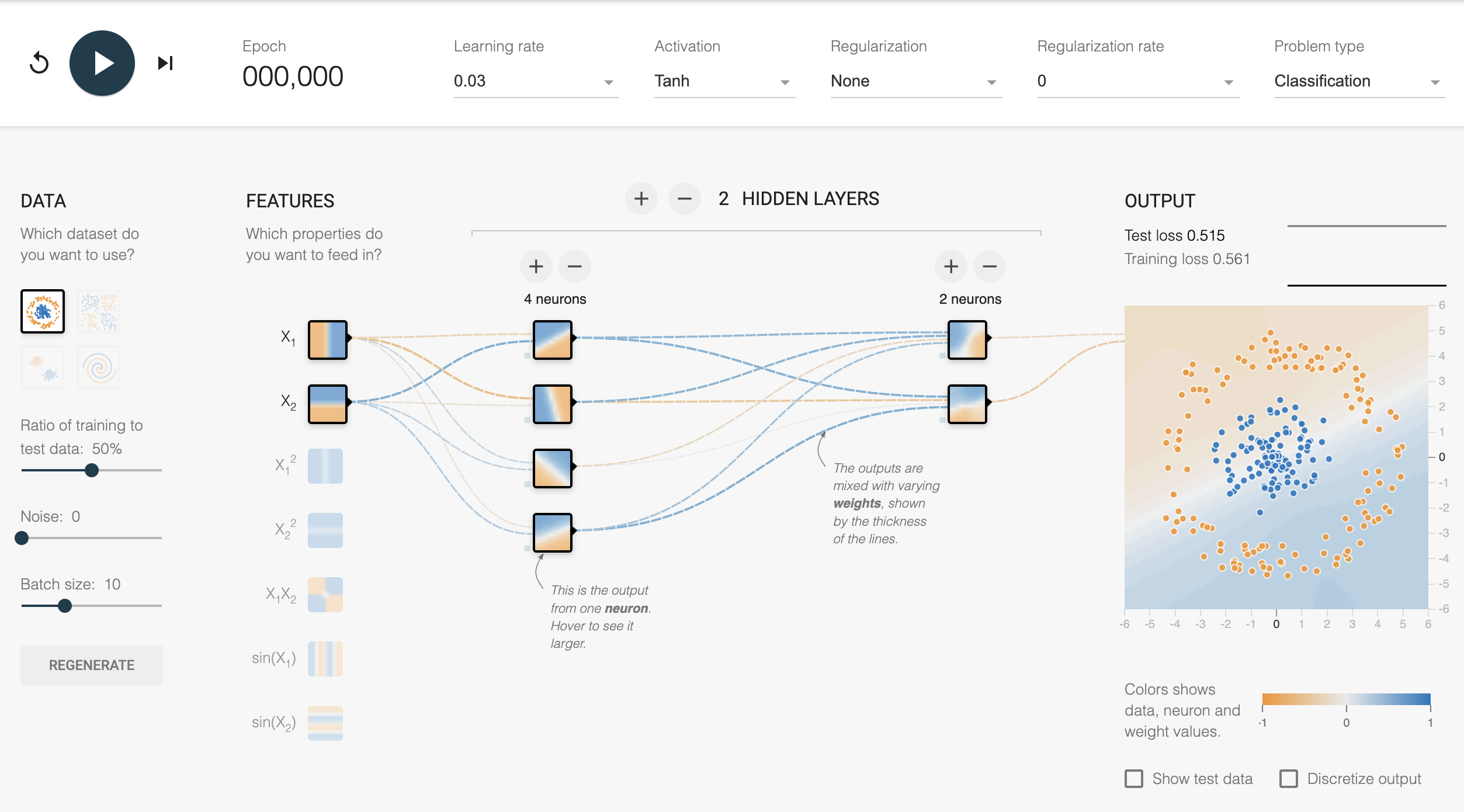 TensorFlow Playground.
TensorFlow Playground.
Source: playground.tensorflow.org
Next Steps
Check out Part 2 of the machine learning series covering how algorithms learn from data, as well as ways to ensure you train a good model by addressing model complexity, overfitting and data splits.
If you really want to jump into ML, I also recommend Andrew Ng’s fantastic Stanford CS229 lecture series available on YouTube. Have fun!