This is Part 3 in the machine learning series, covering productionisation of models. Part 1 covers an overview of machine learning and common algorithms, while Part 2 covers model training and learning from data.
What is machine learning productionisation?
Machine learning productionisation can mean different things. It could mean taking a pre-trained ML model and making it available as an API. It could also involve building a pipeline for data preparation, model training, optimisation, and validation.
Hopefully you are also monitoring your productionised system to ensure everything is running well, for example catching unexpected errors or measuring model drift on new data over time. If you’re able to reproduce experimental results, iterate quickly and push to production automatically then you get bonus points.
Regardless of the precise definition, getting machine learning models into a production system and maintaining them over time is hard.
 Source: xkcd.com
Source: xkcd.com
Best practices are emerging to ensure you can successfully prepare data, train a model, validate predictions, deploy, serve and monitor your model.
This post is a 10,000-foot overview of things to consider during the life cycle of a machine learning project and includes pointers to useful resources.
What's covered here?
1) Production software requirements
2) Production ML System Requirements
3) Machine Learning Canvas
4) Google's Rules of Machine Learning
5) Technical debt in Machine Learning systems
6) Automated Machine Learning pipelines - basic to advanced
7) Machine Learning frameworks
8) Final thoughts
Production software requirements
As a baseline, a robust production ML system should adhere to good software engineering practices. These foundations must be solid to successfully deploy and operationalise ML models, which come with additional challenges.
Baseline examples:
- Instrumentation, logging and error alerting
- Ability to monitor running systems for required metrics
- The system scales to expected load
- Code is source controlled
- Continuous integration/continuous deployment (CI/CD) pipelines
- External (non-hardcoded) configuration
- Following company coding best practices
- Unit tests to enable confident refactoring
- Integration tests to catch bugs early
Atlassian has a series of articles on software best practices that you may find useful.
Production ML System Requirements
ML systems have additional requirements over and above traditional software systems due to their reliance on training data to construct a model
Data is as important to ML systems as code is to traditional software. Also, many of the same issues affecting code affect data as well, for example versioning.
A comparison of traditional programming vs ML is shown in this diagram. It highlights the shift in thinking required for constructing models and learning rules from data.
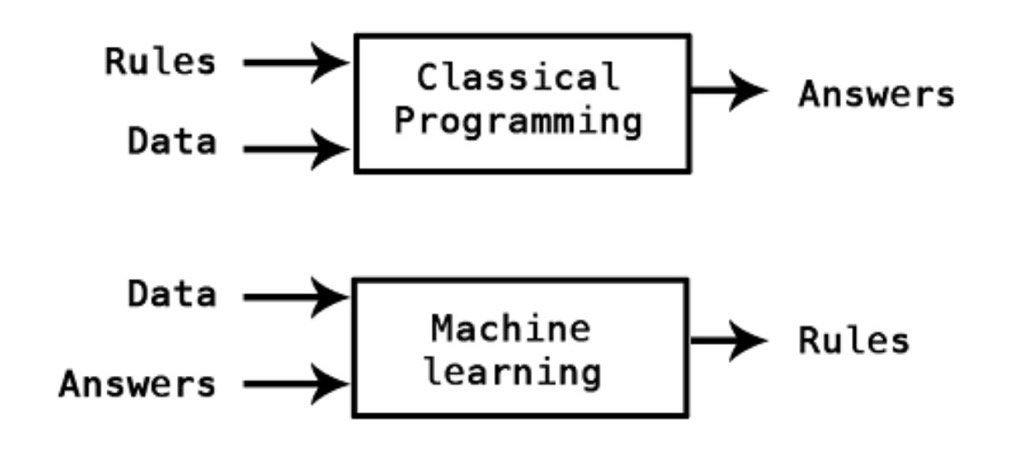 Classical programming contrasted with machine learning
Classical programming contrasted with machine learning
Source: twitter.com/kpaxs
There are several emerging fields growing to address the ML system life cycle.
- Data Engineering - designing and building systems for collecting, storing, processing and analysing data at scale.
- ML Engineering - intersection of machine learning and software engineering; bringing solid engineering principals to building ML models.
- MLOps - intersection of machine learning, data engineering and DevOps; deployment, health, diagnostics and governance of production ML models.
- DataOps - manages the entire data lifecycle from source to value.
- ModelOps or AIOps - extends MLOps and manages all model lifecycles across a company ensuring technical, business and compliance KPI’s.
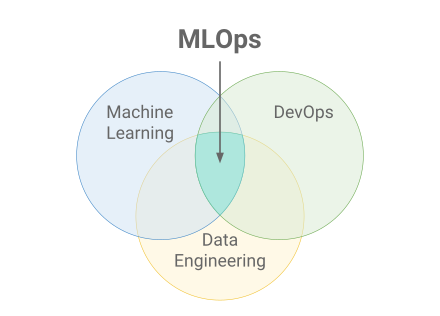 Source: Wikipedia
Source: Wikipedia
These fields are still being defined and created and some may disappear in time. What these descriptions highlight is the interdisciplinary nature required to successfully productionise ML models.
Highly desirable ML system requirements:
- Reproducible model training and validation
- Data lineage for data prep, issue tracing and auditability
- Model versioning with metadata
- Protection from data leakage when training
- Correspondence between training data features and operationalised model data features
- Ability to roll back to previous model (and the corresponding input data features)
- Scalable model prediction serving to meet expected load
- Automated deployment for your use case (e.g. real time/batch predictions)
Desirable ML system requirements:
- Initial requirements scoping (e.g. via Machine Learning Canvas)
- Ability to track multiple training experiments with different data features and hyperparameters
- Scalable model training for expected data size and compute requirements
- Clear tracking of how features were generated
- Automated confidence intervals for data quality (input) and predictions (output)
- Automated model re-training and validation
- Feature store for data reuse and reproducibility
- Ability to track model drift over time (e.g. continuous validation after deployment)
Update Nov 2022:
Operationalizing Machine Learning: An Interview Study from University of California, Berkeley is a great read. It covers interviews with 18 MLEs working across many applications and summarises common practices for successful ML experimentation, deployment, sustaining production performance, pain points and anti-patterns.
Machine Learning Canvas
It’s worth remembering that not all models need to be productionised. Before going down this path hopefully you’ve determined that the value from productionising a model is greater than the cost of productionising and the associated ongoing system maintenance.
The Machine Learning Canvas (adapted from the popular Lean Canvas) identifies requirements, problems and scope of an ML model and is useful to get all parties on the same page early in an ML project.
It helps describe how your ML system will turn predictions into value for end-users, which data it will learn from, and how to make sure it will work as intended. It also helps anticipate costs, identify bottlenecks, specify requirements, and create a roadmap.
 Source: www.ownml.co/machine-learning-canvas
Source: www.ownml.co/machine-learning-canvas
Google's Rules of Machine Learning
Google has published their machine learning best practices (Rules of Machine Learning) and has deep wisdom.
These 4 points are recommended when starting to productionise ML:
- Make sure your pipeline is solid end to end
- Start with a reasonable objective
- Add common–sense features in a simple way
- Make sure that your pipeline stays solid
Followed by this wise caveat: “This approach will work well for a long period of time. Diverge from this approach only when there are no more simple tricks to get you any farther. Adding complexity slows future releases.”
There are 43 rules in total. Here are some highlights:
- Rule #4: Keep the first model simple and get the infrastructure right
- Rule #5: Test the infrastructure independently from the machine learning
- Rule #8: Know the freshness requirements of your system
- Rule #9: Detect problems before exporting models
- Rule #11: Give feature columns owners and documentation
- Rule #14: Starting with an interpretable model makes debugging easier
- Rule #16: Plan to launch and iterate
- Rule #29: The best way to ensure that you train like you serve: save the set of features at serving time and pipe them to a log to training with later
- Rule #31: Beware that if you join data from a table at training and serving time, the data in the table may change
- Rule #32: Re-use code between your training pipeline and your serving pipeline whenever possible
Technical debt in Machine Learning systems
It’s helpful to know what you’re getting into. If you are new on this journey, the paper Hidden Technical Debt in Machine Learning Systems is a must-read.
Here’s the gist:
“ML systems have a special capacity for incurring technical debt, because they have all of the maintenance problems of traditional code plus an additional set of ML-specific issues. This debt may be difficult to detect because it exists at the system level rather than the code level. Traditional abstractions and boundaries may be subtly corrupted or invalidated by the fact that data influences ML system behaviour. Typical methods for paying down code level technical debt are not sufficient to address ML-specific technical debt at the system level.”
“Code dependencies can be identified via static analysis by compilers and linkers. Without similar tooling for data dependencies, it can be inappropriately easy to build large data dependency chains that can be difficult to untangle.”
This image summarises the paper very well and puts the core ML code into perspective when productionising:
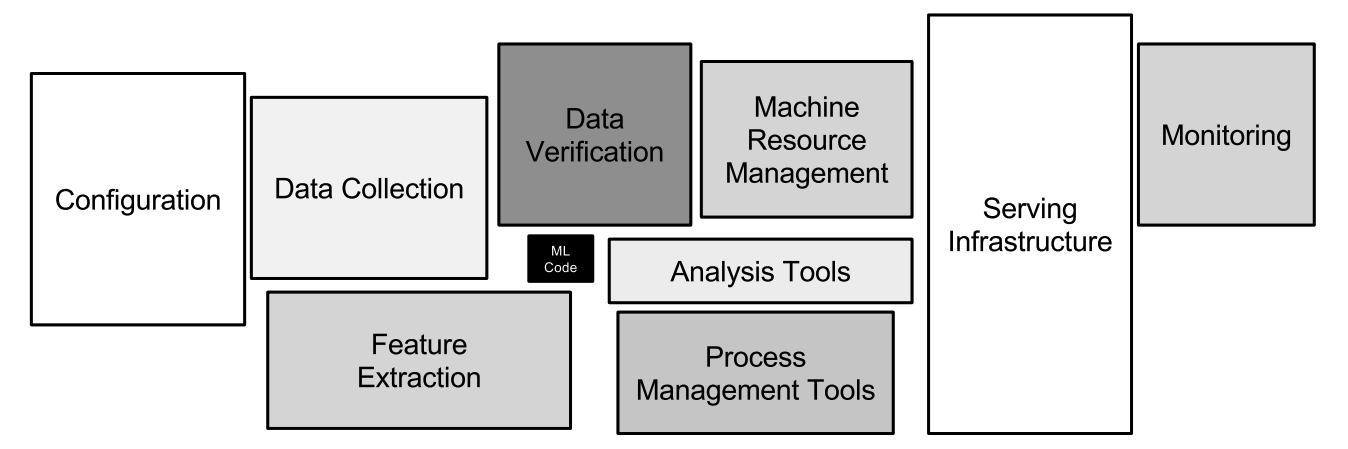 Source: Hidden Technical Debt in Machine Learning Systems (Sculley et al.)
Source: Hidden Technical Debt in Machine Learning Systems (Sculley et al.)
Automated Machine Learning pipelines - basic to advanced
There are several steps in a full ML pipeline. Some steps may be manual at first, especially when proving value to the business.
The key is to understand that the manual steps should be automated in time rather than continuing to accumulate tech debt and potentially produce error-prone results. It is best to understand this commitment at the start.
A productionised predictive ML model is one piece with a fair bit going on, and the best place to start.
Further down the track data quality, data splits, feature engineering, model optimisation and training comprise other pieces.
1. Prediction only ML pipeline
The first step is to productionise the trained model to make automated predictions on unlabelled data.
This diagram only shows the input data and output prediction flow - it doesn’t address where the data comes from or how the predictions are used.
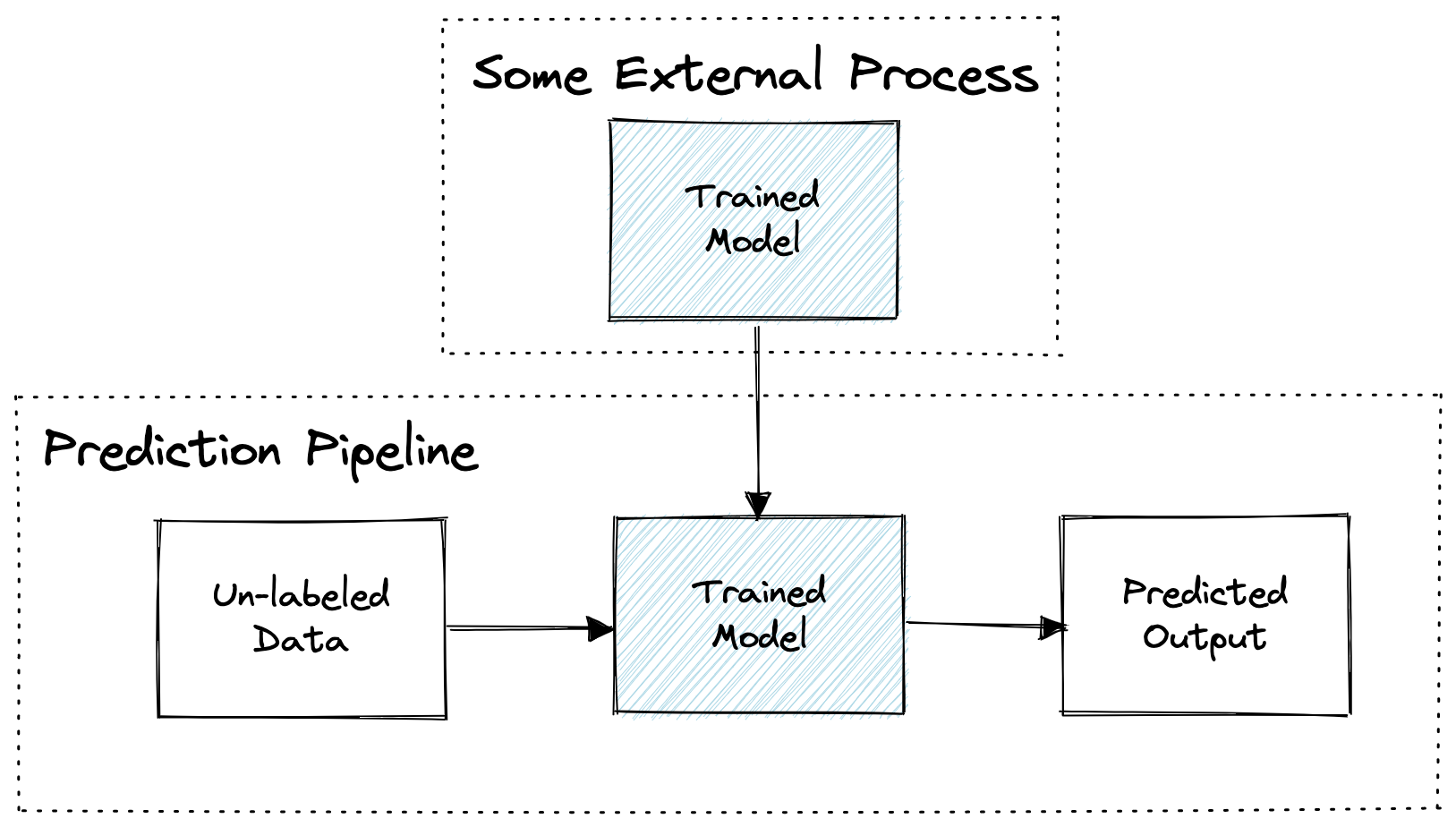 Prediction only ML pipeline
Prediction only ML pipeline
Source: Author
2. Basic ML pipeline with training and testing
An extension is to automate the data splits, model training and performance evaluation. This helps with reproducibility, removes error-prone manual steps, and saves time.
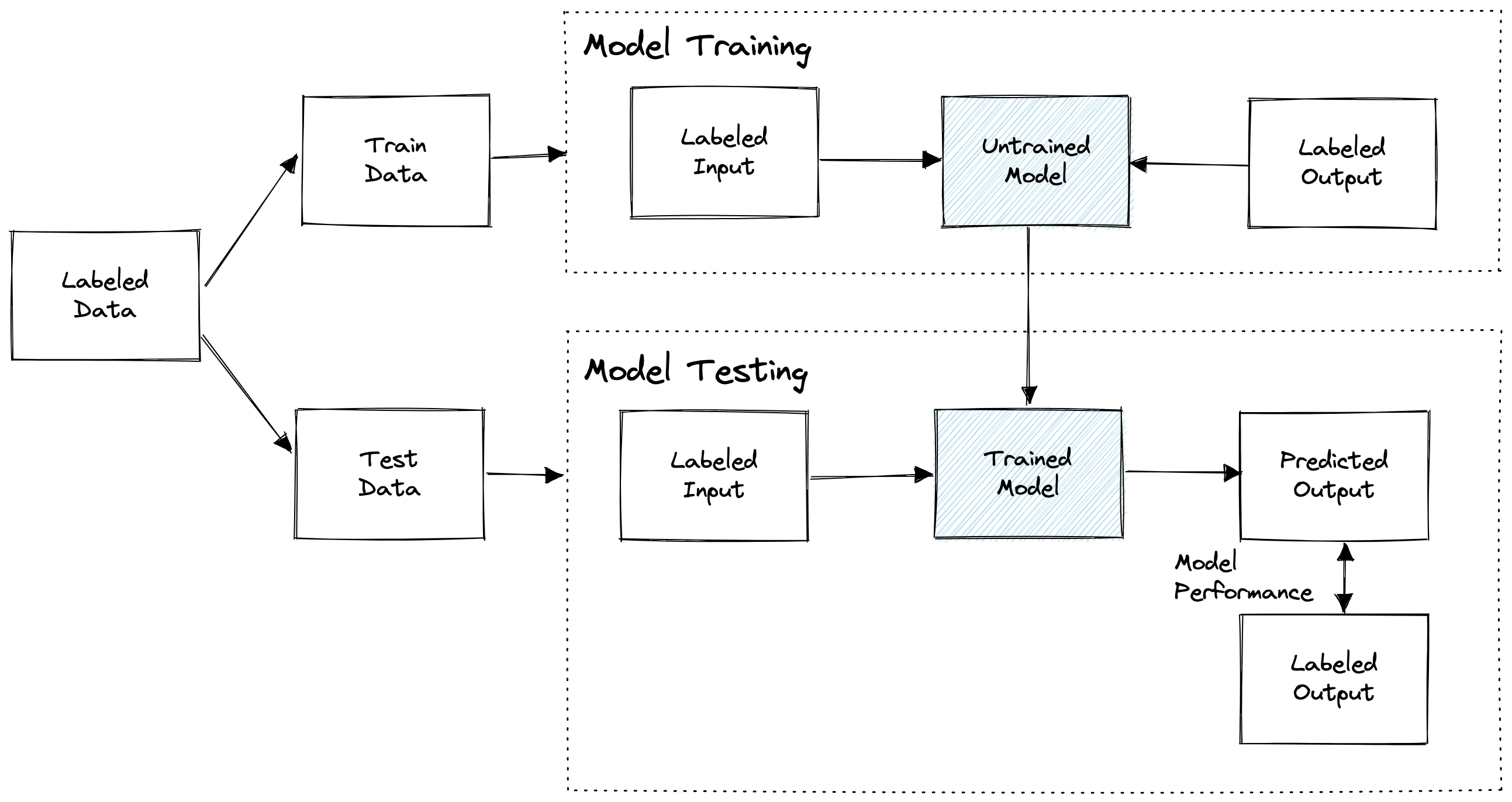 Basic ML pipeline with training and testing
Basic ML pipeline with training and testing
Source: Author
3. Pipeline with multiple trained models, evaluation, selection and testing
A next possible step is to automate training and evaluation of multiple models with multiple training input data feature sets.
This gets complex very quickly and requires pre-requisite systems to be in place to run efficiently. The emerging field of MLOps (machine learning operations) is building tools, techniques and companies to handle these type of scenarios.
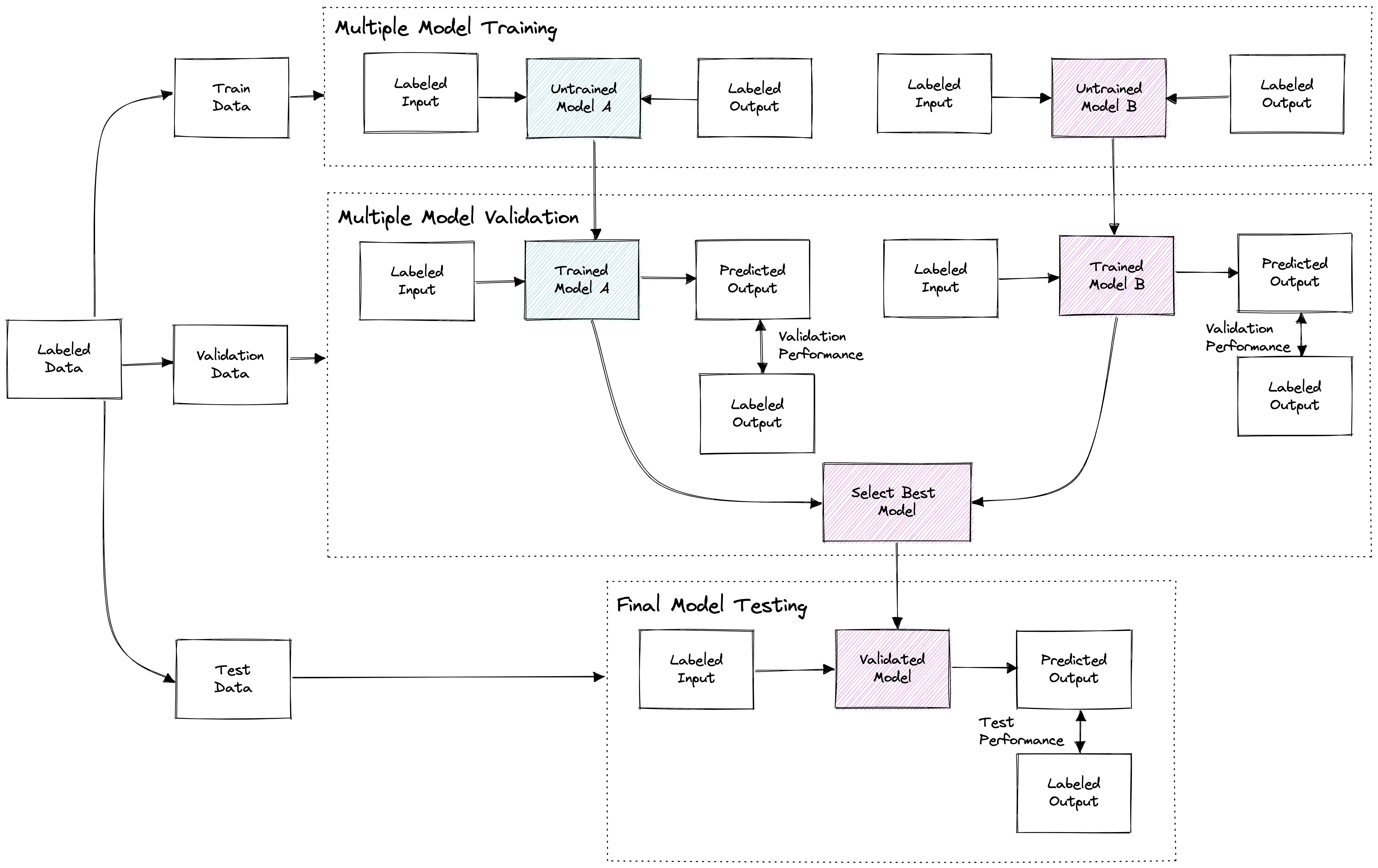 Pipeline with multiple trained models, evaluation, selection and testing
Pipeline with multiple trained models, evaluation, selection and testing
Source: Author
4. Deploying and monitoring
What isn’t addressed in the pipeline diagrams above is model deployment, serving and monitoring.
This is dependent on many things: your current infrastructure, who will be consuming the model results, performance requirements, size of data etc.
For example, if you have a Kubernetes cluster available, you could containerise your model and deploy using Kubeflow. Or maybe your company uses AWS and your model is small? In this case you could use existing deployment practices and deploy to Lambda or else utilise the managed AWS SageMaker service. If you’re just starting out, you may be able to set up a Python webserver and utilise a framework like FastAPI to serve model results.
Whichever path you choose, follow the software and ML system best practices described above where possible.
Machine Learning frameworks
To round off this post, here are a some open-source and commercial offerings that you could check out.
Machine Learning Frameworks
It is best to build on the shoulders of giants. Here are some open-source ML frameworks you might find want to explore in your ML productionisation journey:
- MLFlow (Databricks): An open-source platform for the machine learning lifecycle, experiment tracking focussed.
- KubeFlow (Google): The Machine Learning Toolkit for Kubernetes. Pipeline focussed. At its core, a container orchestration system
- Weights & Biases: Build better models faster with experiment tracking, dataset versioning, and model management
- Metaflow (Netflix): Build and manage real-life data science projects with ease
- Neptune: Manage all your model building metadata in a single place
- Comet: Manage and optimize the entire ML lifecycle, from experiment tracking to model production monitoring.
- Ludwig: Data-centric declarative deep learning framework
- Kedro: A framework for creating reproducible, maintainable and modular data science code.
- Dagster: An orchestration platform for the development, production, and observation of data assets.
- ClearML (commercial): CI/CD to streamline your ML workflow. Experiment Manager, MLOps and Data-Management.
- Valohai (commercial): Train, Evaluate, Deploy, Repeat. Valohai is the only MLOps platform that automates everything from data extraction to model deployment.
- Feast: An open-source feature store. It is the fastest path to operationalizing analytic data for model training and online inference.
- Pachyderm: Automate data transformations with data versioning and lineage.
Managed Cloud ML Services
The big cloud players are in MLOps now too.
- AWS SageMaker - Build, train, deploy, and manage ML models
- Google Vertex AI - Build, deploy, and scale ML models
- Azure MLOps - Automate and accelerate the machine learning lifecycle
- Databricks ML - Data-native and collaborative ML solution for the full ML lifecycle
- DataRobot - Center of Excellence for Machine Learning Operations and Production AI
- Dataiku - Deploy, monitor, and manage machine learning projects in production
- Valohai - Train, Evaluate, Deploy, Repeat. Automates everything from data extraction to model deployment
- Gradient - Develop, track, and collaborate on Deep Learning models
- Polyaxon - Reproduce, automate, and scale your data science workflows with production-grade MLOps tools
- neptune.ai - Log, store, display, organize, compare and query all your MLOps metadata
- Tecton - Enterprise Feature Store for Machine Learning
See more platforms here: mlops.neptune.ai
Final thoughts
The machine learning space is evolving rapidly and it’s great to see best practices and tools emerging to make productionisation of models faster and more robust. However, there is still a long way to go!!
 Source: xkcd.com
Source: xkcd.com
Additional resources
General Resources
- awesomepython.org MLOps - A collection of GitHub repositories related to MLOps
- ml-ops.org - Great MLOps resource by innoq
- mymlops.com - Build your MLOps stack by Tanel Sarnet and Nathalia Campos
- Operationalizing Machine Learning: An Interview Study arxiv paper by Shankar et al, 2022
- Machine Learning Operations (MLOps): Overview, Definition, and Architecture arxiv paper by Kreuzberger et al, 2022
- MLOps Spanning Whole Machine Learning Life Cycle: A Survey arxiv paper by Zhengxin et al, 2023
- The Big Book of MLOps (pdf) by Databricks, 2022
- MLOps - A Holistic Approach (pdf) by wandb.ai, 2022
- Practitioners guide to MLOps - A framework for continuous delivery and automation of ML by google cloud, 2021
- Software Engineering for Machine Learning - A Case Study by Microsoft, 2019
- MLOps Guide - An MLOps Guide to help projects and companies to build more reliable MLOps environment.
- awesome-mlops - A curated list of awesome MLOps tools
- MLOps.community on youtube - Machine Learning Operations best practices from engineers in the field
- MLOps.community on youtube - Machine Learning Operations best practices from engineers in the field
Study Resources
- mlops-zoomcamp - Free MLOps course from DataTalks.Club
- MLOps-Basics - A series on the basics of MLOps (model building, monitoring, config, testing, packaging, deployment, cicd, etc)
- Microsoft ML ISE Playbook - Microsoft ML practices in ISE. ISE works with customers on developing ML models and putting them in production.