If you're looking to deploy high-performance LLMs on Google Vertex AI, this post will show you how to leverage vLLM's speed and scalability with a few simple deployment steps using Google’s custom vLLM docker images.
What is vLLM?
")
vLLM is an efficient and high-performance inference and serving framework for many types of large language models (LLMs). It is designed to maximise throughput and minimise memory usage, making it particularly useful for deploying LLM’s in production.
It can be used both as:
a Python library (e.g. import vllm)
or as a CLI server (e.g. vllm serve Qwen/Qwen2.5-7B-Instruct --args), with an option to adhere to the common OpenAI API standard.
vLLM seamlessly supports many models on Hugging Face, including:
Transformer-like LLMs (e.g., Llama)
Mixture-of-Expert LLMs (e.g., Mixtral, Deepseek-V2 and V3)
Embedding Models (e.g. E5-Mistral)
Multi-modal LLMs (e.g., LLaVA)
Originally developed in the Sky Computing Lab at UC Berkeley, vLLM has evolved into a community-driven project with contributions from both academia and industry.
The team behind vLLM started with a new KV cache algorithm called PagedAttention, and also built the open-source server: https://github.com/vllm-project/vllm

In Dec 2024 vLLM became a PyTorch ecosystem project, and joined the PyTorch ecosystem family!
Why is vLLM fast? 🚀
vLLM has state-of-the-art serving throughput, with configurable options for:
Efficient management of attention key-value (KV) cache memory using PagedAttention
PagedAttention is a memory-efficient mechanism used to optimise KV cache (and is orthogonal to other caching mechanisms like FlashAttention)
Continuous batching of incoming requests
Speculative decoding, a technique designed to speed up text generation by predicting multiple tokens in advance and verifying them with a draft model and reducing latency
Chunked prefill - an inference optimisation technique that improves GPU utilisation during prefill (processing input tokens before generation begins)
Model quantization support: GPTQ, AWQ, INT4, INT8, and FP8
Optimised CUDA kernels, including integration with FlashAttention
Tensor parallelism and distributed serving on multiple GPUs
vLLM isn’t the only kid in town, here are some alternative high performance inference engines:
Google’s VertexAI API I/O interface

vLLM can be deployed on a variety of GPU hardware and cloud options including AWS SageMaker, Microsoft Azure, on-prem, and many other providers.
In this post we’ll look specifically at deploying a Hugging Face or custom trained model with vLLM to Google’s Vertex AI platform, and how to work around the fixed Vertex AI API interface.
As you may have seen in the VertexAI endpoint test UI, the API specifies a very specific schema for API requests and responses when making predictions:
VertexAI prediction request schema:
{
"instances": [ "<instances here>" ]
}VertexAI prediction response schema:
{
"deployedModelId": "123412341234",
"model": "projects/456745674567/locations/us-central1/models/678967896789",
"modelDisplayName": "my-custom-model-vllm-qwen25-1pt5b-inst",
"modelVersionId": "1",
"predictions": [ "<predictions here>" ]
}vLLM however doesn't natively support this request/response schema with “instances” and “predictions” keys, instead it's commonly deployed with the OpenAI API interface. So what should we do?
GCP vLLM Docker image
Luckily Google publish custom vLLM server docker images for us to use! Thanks google.

At the time of writing (early Feb 2025) the latest image tag is us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve:20250202_0916_RC00 (at 12.8 GB) which if you bash into it, you will find the vLLM version 0.1.dev1+g4f51006.d20250202 (via cat /workspace/vllm/vllm/_version.py)
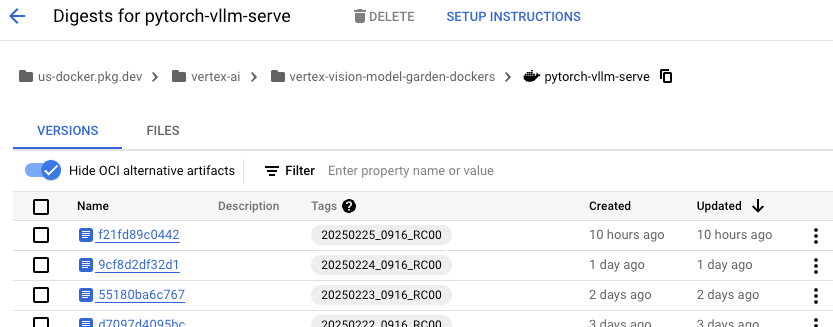
This doesn't match any vLLM release versions, and a possible reason is that Google patch vLLM (using something similar to this patch file). The closest I have found is cat /workspace/vllm/README.md and looking at the date of the most recent "Latest News", which for tag 20250202_0916_RC00 is 2024/11 which would match https://github.com/vllm-project/vllm/blob/v0.6.4/README.md)
These customisations add several VertexAI compatibility features:
Support for downloading a custom model from Google Cloud Storage (GCS) via a gs://<bucket>/<path>/<model> specifier
Support for downloading a custom model from AWS S3 via s3://<bucket>/<path>/<model>
A way to call the chat/completions endpoint or the generate endpoint (determined by adding "@requestFormat": "chatCompletions" to the instance)
/ping endpoint required for Vertex deployment
Given this image, we can easily deploy it to VertexAI as a model, and specify any vLLM server args to control its operation.
Deploy a Hugging Face model to a VertexAI endpoint

For example, here we deploy vLLM with the Hugging Face Qwen/Qwen2.5-1.5B-Instruct model and server args --max-model-len=4156,--gpu-memory-utilization=0.95,--disable-log-stats:
MODEL_NAME="Qwen/Qwen2.5-1.5B-Instruct"
IMAGE_NAME=my-custom-model-vllm-qwen25-1pt5b-inst
REPOSITORY="us-docker.pkg.dev/vertex-ai/vertex-vision-model-garden-dockers/pytorch-vllm-serve"
REPOSITORY_BUILD="20250202_0916_RC00"
# Upload VertexAI model
gcloud ai models upload \
--project="$PROJECT_NAME" \
--region="$REGION" \
--display-name="$IMAGE_NAME" \
--container-image-uri="$REPOSITORY:$REPOSITORY_BUILD" \
--container-command="python,-m,vllm.entrypoints.api_server" \
--container-args="--host=0.0.0.0,--port=7080,--model=$MODEL_NAME,--max-model-len=4156,--gpu-memory-utilization=0.95,--disable-log-stats" \
--container-ports=7080 \
--container-health-route="/ping" \
--container-predict-route="/generate"
# Deploy to a VertexAI endpoint, specifying machine and GPU type:
gcloud ai endpoints deploy-model "$ENDPOINT_ID" \
--project="$PROJECT_NAME" \
--model="$MODEL_ID" \
--display-name="$IMAGE_NAME" \
--region="$REGION" \
--min-replica-count=1 \
--max-replica-count=1 \
--traffic-split=0=100 \
--machine-type=g2-standard-4 \
--accelerator=type=nvidia-l4,count=1 \
--enable-access-loggingDeploy a custom model from Cloud Storage

If you want to deploy a custom model (e.g. a merged base-model with finetuned LoRA weights) from a GCS bucket, you only need to specify the --artifact-uri gcloud argument pointing to your bucket, and omit the --model=$MODEL_NAME argument to vLLM.
Specifying --artifact-uri will set the AIP_STORAGE_URI environment variable to be an internal Google managed GCS bucket name (e.g. gs://caip-tenant-/2051094961151016960/artifacts) which is a copy of the user specified bucket, and a model value of None will ensure the patched google Docker image attempts to load from AIP_STORAGE_URI. Reference source code as I couldn't find actual docs on this feature.
Deploy a custom model, as described in the previous paragraph:
MODEL_ARTIFACT_URI="gs://<bucket>/<path>/Qwen-Qwen2.5-1.5B-Instruct/model-merged"
IMAGE_NAME=my-custom-model-vllm-gcs
gcloud ai models upload \
--project="$PROJECT_NAME" \
--region="$REGION" \
--display-name="$IMAGE_NAME" \
--container-image-uri="$REPOSITORY:$REPOSITORY_BUILD" \
--container-command="python,-m,vllm.entrypoints.api_server" \
--container-args="--host=0.0.0.0,--port=7080,--disable-log-stats" \
--container-ports=7080 \
--container-health-route="/ping" \
--container-predict-route="/generate" \
--artifact-uri="$MODEL_ARTIFACT_URI"It's worth noting that we're not locked into VertexAI with vLLM, here are some Kubernetes resources for GKE or platform-agnostic k8s cluster deployment:
https://cloud.google.com/kubernetes-engine/docs/tutorials/serve-multiple-gpu
https://github.com/vllm-project/production-stack?tab=readme-ov-file#deployment
How do I call the model?

Although vLLM has the OpenAI API, since the server is wrapped, we need to call it like like any VertexAI endpoint with the “instances” key:
VertexAI endpoint request example:
request_body = {
"instances": [
{
"@requestFormat": "chatCompletions",
"messages": [
{
"role": "system",
"content": "<system_prompt>"
},
{
"role": "user",
"content": "<user_content>"
}
],
"max_tokens": 4096,
"temperature": 0.1
},
{ "<more instances here" }
]
}
headers = {
"Authorization": f"Bearer {get_access_token()}",
"Content-Type": "application/json",
}
endpoint_url = f"https://{region}-aiplatform.googleapis.com/v1/projects/{project_name}/locations/{region}/endpoints/{endpoint_id}:predict"
endpoint_timeout = 30
response = requests.post(endpoint_url, headers=headers, json=request_body, timeout=endpoint_timeout)The prediction response matches the order of the input instances - there is no "id" field to join back to get input/output results, just use the list index.
Also note that if you exclude "@requestFormat": "chatCompletions" then you will call the generate completion and not the chat completion. (Example patch code showing this branch). For a refresher on the difference between Chat vs. Completion, see this blogpost.
What performance metrics matter?
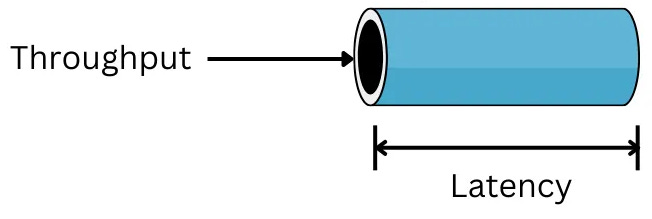
Latency: Elapsed time of an event Throughput: The number of events that can be executed per unit of time
Throughput vs. Latency Restaurant Analogy
Latency: how long it takes to prepare and serve a single meal after a customer places an order. If the chef focuses on one order at a time, it gets served quickly (low latency), but the number of customers served per hour is low.
Throughput: total number of meals the kitchen can prepare and serve per hour. If the chef prepares multiple orders together in batches, the kitchen can serve more people in total (high throughput), but each individual order may take longer to be completed.
The specifics of which Latency vs Throughput metrics are "good" depends on the project requirements and how the user will interact with the LLM. vLLM is engineered to efficiently balance throughput and latency in production settings by leveraging continuous batching and an asynchronous engine
According to an AnyScale benchmark, on an NVIDIA A100 GPU with 40GB of GPU RAM, continuous batching with vLLM achieved 6,121 tokens/sec when max-tokens was set to 32, and 1,898 tokens/sec when max-tokens was set to 1,536. The same benchmark also reports vLLM to have the lowest latency compared to other frameworks and claim that continuous batching also improves median latency.
Additional performance notes can be found in this blog post: https://blog.vllm.ai/2024/09/05/perf-update.html
Which models can we serve on an L4 GPU with 32GB RAM?

Here is a brief set of results regarding the Qwen2.5 series of models on a single machine configuration of: a g2-standard-8 (32 GB RAM) machine with a single L4 GPU attached.
Note that there are several factors determining if a model can serve results, key being:
the number of model parameters (here 1.5B, 7B, 14B for Qwen2.5-Instruct)
the vLLM server argument --max-model-len that can optionally set model context length to less than the default value of 16k
level of model quantisation, if any
Here are some sample results:
✅ Qwen/Qwen2.5-1.5B-Instruct is good and easily fits
✅ Qwen/Qwen2.5-7B-Instruct with --max-model-len=4156 is good
❌ Qwen/Qwen2.5-7B-Instruct with default max-model-len of 16k cannot be allocated on endpoint deployment
❌ Qwen/Qwen2.5-14B-Instruct is too large for the L4 resulting in torch.OutOfMemoryError: CUDA out of memory error
✅ Qwen/Qwen2.5-14B-Instruct-AWQ quantised model is good
Selected vLLM tuning options
There are many vLLM engine arguments, which you can see here: https://docs.vllm.ai/en/stable/serving/engine_args.html
Here are some notable arguments that could have a big impact on serving performance:
--disable-log-stats (Disable logging statistics)
--dtype=float16 OR bfloat16 (For memory savings. Default: “auto”: “auto” will use FP16 precision for FP32 and FP16 models, and BF16 precision for BF16 models. “half” for FP16 | "half" recommended for AWQ quantization.)
--gpu-memory-utilization=0.95 (The fraction of GPU memory to be used for the model executor. Default is 0.9)
--swap-space=XX (CPU swap space size GiB per GPU. Default is 4)
--tensor-parallel-size=N (Number of tensor parallel replicas. Default: 1. Try multi-gpu deployment?)
--artifact-uri="$MODEL_ARTIFACT_URI" (for testing custom GCS models)
--enable-prefix-caching (Improve prefilling phase. Automatic Prefix Caching caches the KV cache of existing queries)
--disable-sliding-window (Disables sliding window, capping to sliding window size.)
--seed (Random seed for operations, useful for reproducibility. Default: 0)Conclusion
vLLM is a highly efficient and practical framework for deploying LLMs in production, especially when integrated with Google's VertexAI. With features like PagedAttention, continuous batching, speculative decoding, and quantisation support, vLLM can provide exceptional performance, balancing throughput and latency.
Google's custom Docker images for VertexAI simplify model deployment by seamlessly aligning vLLM’s OpenAI-compatible API with VertexAI's requirements, making GCP productionisation straight forward.
References
https://github.com/vllm-project/production-stack?tab=readme-ov-file#deployment
https://docs.vllm.ai/en/latest/performance/optimization.html
https://arxiv.org/abs/2309.06180 (PagedAttention paper)
https://www.baseten.co/blog/continuous-vs-dynamic-batching-for-ai-inference/
https://www.anyscale.com/blog/continuous-batching-llm-inference
https://www.hyperstack.cloud/blog/case-study/what-is-vllm-a-guide-to-quick-inference